loc와 iloc의 차이
- loc
- 데이터프레임의 행이나 컬럼에 label이나 boolean array로 접근
- location의 약어로, 인간이 읽을 수 있는 label 값으로 데이터에 접근
- iloc
- 데이터프레임의 행이나 컬럼에 인덱스 값으로 접근
- integer location의 약어로, 컴퓨터가 읽을 수 있는 indexing 값으로 데이터에 접근
- 데이터 생성
import pandas as pd
df = pd.DataFrame({'a' : [i for i in range(1, 11)], 'b' : [i for i in range(11, 21)], 'c' : [i for i in range(21, 31)]})df
-문제 : a, b열을 추출하기
df['a', 'b']
df[['a', 'b']]
주의해야할 점
각각의 위치 또는 이름으로 인덱싱 할 때는 괄호를 두개 [[]]를 씌워야함
type(df[['a', 'b']]pandas.core.frame.DataFrame
-문제 : 첫 번째 행의 데이터를 출력하기
df[0]
1) loc를 통한 인덱싱
df.loc[0]a 1
b 11
c 21
Name: 0, dtype: int64
- loc를 이용한 슬라이싱
df.loc[2:4]
- 인덱스가 문자로 이루어진 경우
index = ['a', 'b', 'd', 'c', 'e', 'f', 'g', 'g', 'h', 'i']
df = pd.DataFrame({'a' : [i for i in range(1, 11)], 'b' : [i for i in range(11, 21)], 'c' : [i for i in range(21, 31)]}, index = index)
df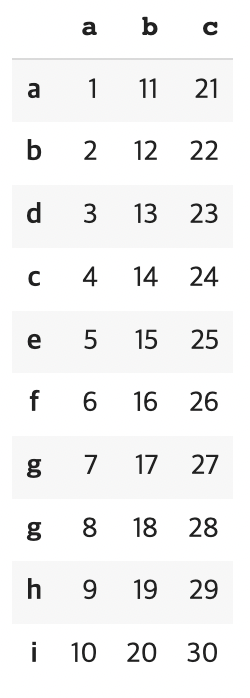
df.loc['g']
df.loc['c':]
-문제 : 열이 a, c 이며 인덱스가 g, i 인 데이터를 출력하기
df.loc[['g', 'i'], ['a', 'c']]
2) iloc를 통한 인덱싱
-문제 : 처음부터 5번째 까지의 데이터와 첫 번째 열과 세 번째 열의 데이터를 추출하기
df = pd.DataFrame({'a' : [i for i in range(1, 11)], 'b' : [i for i in range(11, 21)], 'c' : [i for i in range(21, 31)]})
df
df.iloc[:5, [0, 2]]
- 인덱스가 문자로 이루어진 경우
index = ['a', 'b', 'd', 'c', 'e', 'f', 'g', 'g', 'h', 'i']
df = pd.DataFrame({'a' : [i for i in range(1, 11)], 'b' : [i for i in range(11, 21)], 'c' : [i for i in range(21, 31)]}, index = index)
df
df.iloc[:5, [0, 2]]
'study📚 > python' 카테고리의 다른 글
| [python/파이썬] 데이터 전처리 - 정렬 sort_index(), sort_values() (0) | 2022.07.25 |
|---|---|
| [python/파이썬] 데이터 전처리 - 조건에 맞는 데이터 추출 (0) | 2022.07.23 |
| [python/파이썬] 데이터 전처리 - 시리즈(Series) (0) | 2022.07.22 |
| 데이터 전처리 - copy를 이용한 데이터 복사 (0) | 2022.07.22 |
| [python/파이썬] 데이터 전처리 - 데이터 프레임 생성, 칼럼명 추출/변경 (0) | 2022.07.22 |




댓글